MiniMax-M2.7 开源模型:第一个自己教自己的AI
4月12日通用AI科技公司MiniMax宣布,其最新一代大模型MiniMax M2.7正式开源。这个模型有意思的是——让模型自己优化自己。
自己教自己
按照官方说法,M2.7是第一个”深度参与自身进化”的模型。在开发过程中,模型可以更新自己的记忆、构建几十个复杂的技能、根据实验结果改进自己的学习流程。
听起来有点玄乎,但人家确实给出了具体数据:
- 一个内部版本的M2.7自主优化编程脚手架超过100轮,分析失败轨迹、修改代码、运行评估、决定保留还是回滚,最终性能提升了30%
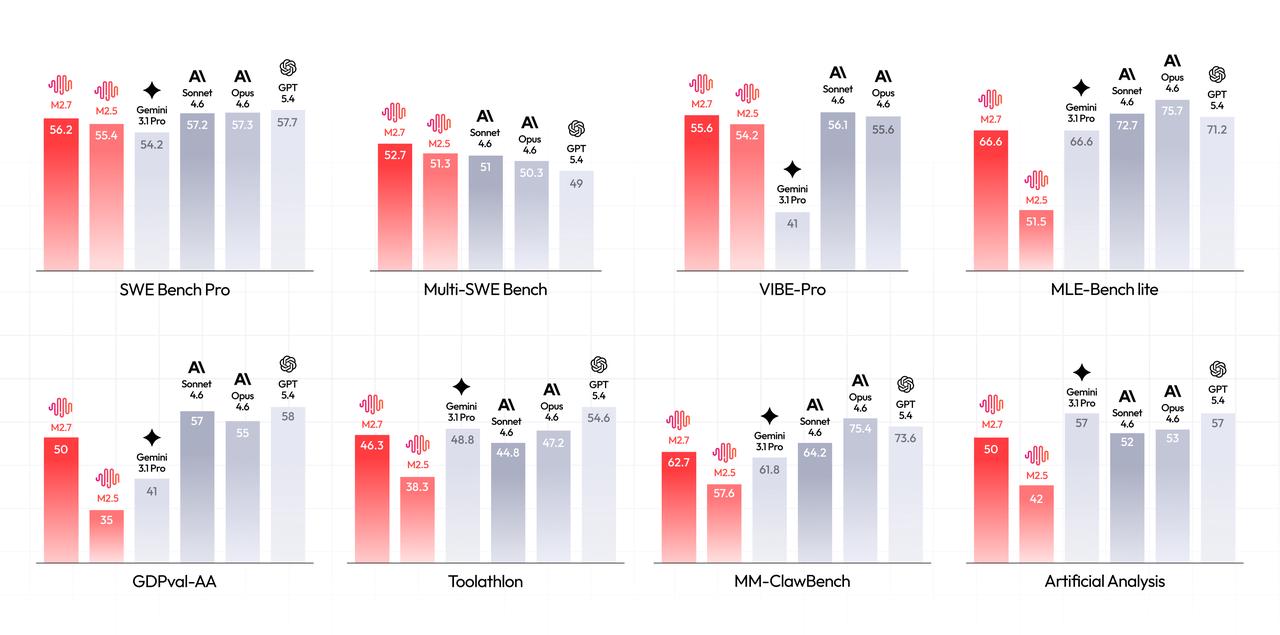
- 在 MLE Bench Lite(22个ML竞赛)上,M2.7达到了66.6%的奖牌率,仅次于 Opus-4.6 和 GPT-5.4
这就好像一个学生,不仅能自学,还能自己出题、自己批改、自己总结改进方向。
编程能力有多强?
作为技术人,我最关心的还是实际编程能力。M2.7 在 SWE-Pro 上达到了56.22%,和 GPT-5.3-Codex 持平。更强的是现实工程场景:
- SWE Multilingual: 76.5分
- Multi SWE Bench: 52.7分
- Terminal Bench 2: 57.0%
- VIBE-Pro: 55.6%
这些数字意味着什么?意味着M2.7不仅能写代码,还能做trace分析、做根因验证、做SRE级别的决策。官方说他们用M2.7把生产环境故障恢复时间压缩到了3分钟以内。
Agent Teams:多Agent协作
M2.7还支持原生Agent Teams,可以实现多Agent协作,而且保持了稳定的角色身份和自主决策能力。这意味着什么?不再是单个AI帮你干活,而是多个AI分工合作,各司其职。
官方还开源了 OpenRoom,是一个交互式Demo,把AI交互放在Web GUI空间里,有实时视觉反馈和场景交互。可以去 openroom.ai 体验一下。
部署方式
开源嘛,最重要的就是能自己部署。MiniMax官方推荐使用 SGLang 或 vLLM 来部署M2.7,同时也支持 Transformers、ModelScope 和 NVIDIA NIM。
推荐参数:temperature=1.0, top_p = 0.95, top_k = 40
开源派的思考
说句实在话,AI自己教自己这个概念不算新,但能把效果做到这个程度的,确实不多。66.6%的奖牌率、3分钟内的故障恢复、76.5的SWE Multilingual分数,这些都不是吹出来的。
但我更好奇的是:当模型开始自己优化自己之后,人类还能不能理解它的进化方向?给它足够的时间,它会不会进化到人类无法理解的程度?
这些问题,可能比模型本身更有意思。

参考资料:
– MiniMax-M2.7 GitHub
– HuggingFace 模型下载
– OpenRoom 交互式Demo
– MiniMax 官方博客
关于作者:开源派,关注开源技术与独立开发。



发表回复